So as part of a recent upgrade I was performing, I upgraded a couple of Netscaler Access Gateways from version 10.1 to version 10.5. The upgrade went very smoothly, no errors, no user calls… for a while. The next day, we started receiving some calls regarding issues with launching apps via Storefront. Some users were receiving the “SSL Error 43: The proxy denied access to…” error with their STA ticket when clicking on their application icons on the web page.
Tracking down the servers based on their STA ID in the ticket, I noticed that users only had issues when they were attempting to authenticate to Windows 2012 R2 delivery controllers. The Windows 2008 R2 delivery controllers were not denying the STA requests. Jumping on one of the Windows 2012 R2 delivery controllers, I noticed the System event log was flooded with Schannel errors for Event ID 36874 (An TLS 1.2 connection request was received from a remote client application, but none of the cipher suites supported by the client application are supported by the server. The SSL connection request has failed.) and Event ID 36888 (A fatal alert was generated and sent to the remote endpoint. This may result in termination of the connection. The TLS protocol defined fatal error code is 40. The Windows SChannel error state is 1205.).
Well, we obviously have an SSL issue, but these codes aren’t exactly pointing me anywhere. Looking up the error code on the RFC page for the TLS protocol (http://tools.ietf.org/html/rfc5246) I found that error code 40 is a handshake failure (you can find this in the A.3 part of the appendix in the Alert Messages section). I can’t remember where exactly I found the enum definition for the Schannel 1205 code, but it basically means that a fatal error was send to the endpoint and the connection was being forcibly terminated. At least I now knew there was an issue with the SSL handshake between the Netscalers and the Windows 2012 R2 delivery controllers. Time for some network tracing.</p>
Firing up Wireshark on the delivery controller, I could see that the connection was getting immediately reset by the server after the Client Hello from the Netscaler.

Expanding the Client Hello packet in the capture, I could see a list of ciphers currently being offered by the Netscaler. (Note – for the sake of easier troubleshooting, I left the default grouping of ciphers in place as it was a large group of widely accepted ciphers until I identified the issue and then trimmed down the cipher list. You should limit the number of ciphers available on the virtual server of your Access Gateway to just what you need and leverage the more current stronger methods available such as AES 256 over RC4 and MD5, etc. if possible.)
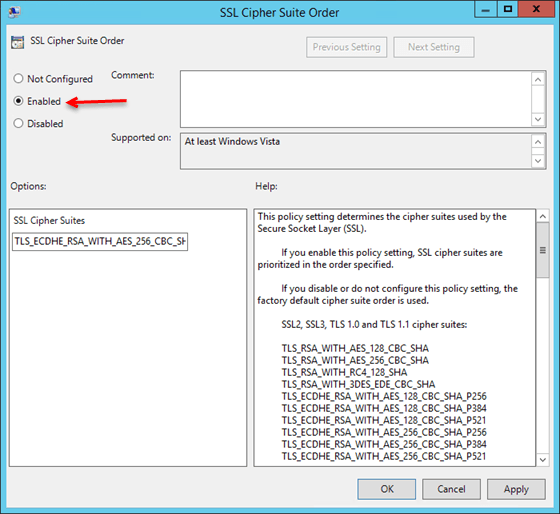
Next, I configured the SSL Cipher Suite Order on the windows server to match what the Netscaler was presenting in the Client Hello packet, at least the top 10 or so. This can be done using either gpedit.msc for local policy or via the Group Policy Management Console as follows:
- In either editor, expand Computer Configuration/Administrative Templates/Network.
- Click on SSL Cipher Suite Order in the SSL Configuration Settings
- Select the Enabled option and then follow the instructions in the Help section of the policy. Basically, all the ciphers you want will be listed on a single line separated by commas with no spaces anywhere.
- You must reboot the server for the changes to take effect.
Even after the reboot, the SChannel errors were still present and the network captures were still showing the handshake failing due to a reset from the server. I’ll save you the time you will spend on re-ordering the ciphers on both the Netscaler and the Windows Server 2012 R2 Delivery Controller along with the multitude of reboots that go with it; it simply won’t work (at least at the time I published this).
I stepped back and decided to try tweaking the TLS protocol versions since I wasn’t getting anywhere with the cipher suites (key exchange algorithms). For the sake of brevity, after much additional testing, headbanging, and googling I was able to get the handshake to work when I disabled TLS 1.2 on the Windows 2012 server. This forced the server to renegotiate using TLS 1.1 with the Netscaler which worked with the cipher suites I tested with that were supported by both the OS and the Netscaler. I did find a nice article supporting this here for additional reference.
To disable TLS 1.2 on the server, you need to modify a registry key:
-
Go to HKLM\SYSTEM\CurrentControlSet\Control\SecurityProviders\SCHANNEL\Protocols.
-
If the TLS 1.2 key does not exists, create it.
-
Inside the TLS 1.2 **key, create another key called **Client.
-
Within the Client key, create two REG_DWORD values:
a. DisabledByDefault (set value to 1).
b. Enabled (set value to 0).
You will need to reboot one more time for the changes to take effect. This finally cleared up my SChannel errors as well as allowed me to add the controllers back as STA’s in the virtual server; in a green status this time.

